Vertical caption placement is our patented solution to a common problem: some videos have text on the bottom of the screen that is important for understanding the video.
Common examples of content that needs vertical caption placement:
Sports scores and stats on the bottom of a screen during a game.
A documentary that displays interview subjects’ title and name when they are introduced.
A lecture capture recording that displays important notes on the whiteboard at the bottom half of the screen.
In each of these cases, placing a caption at the bottom of the frame (the default position) would obscure important text. Instead, the captions be moved to the top of the screen temporarily.
Captions must also be vertically “stable”; they should not jump around in the middle of a sentence, and they should remain in their current position for long enough so that their movement doesn’t overly distract the viewer.
Correct caption placement is an FCC requirement for all American TV, commercials, or films. Our vertical caption placement service helps you meet FCC standards quickly and cost-effectively. See How Vertical Caption Placement Works
Play the video below to see a demo of vertical caption placement.
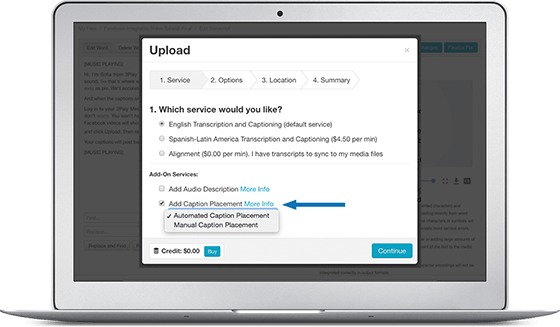
Automatic Vertical Caption Placement
Our automatic vertical caption placement relies solely on an algorithm to detect when repositioning is needed. It produces 95% accurate caption placement.
There are some limitations to automatic caption placement:
If there is text on the top and bottom parts of the screen, it can’t decide which is more important.
Automatic vertical caption placement does not detect faces or graphics in the caption frame.
Caption placement technology is designed to err on the side of moving captions to the top, which results in fewer cases of bottom text obscurity. On rare occasions, the captions are moved to the top needlessly.
Manual Vertical Caption Placement
For content that needs the maximum accuracy possible, manual vertical caption placement introduces an editor’s trained eye to approach 100% accuracy. An editor will review each caption frame in your video to ensure nothing essential is being blocked.
This service is most useful for ensuring that non-text graphics, symbols, or imagery remains unobscured by captions, since automatic placement only detects text on screen.
Supported Caption or Subtitle Formats
The following caption formats that support vertical placement.
SCC
STL
Web-VTT
DFXP
SMPTE-TT
Pricing
Our competitive prices are based on the exact duration of each file. You are charged on a pay-per-use basis and there are no minimums or hidden charges. You can either pay by credit card or we can invoice you. See the complete price list
Turnaround
Turnaround depends on the duration of your files and our capacity at the time of upload. Files are usually completed within a few hours and almost always by the next business day.