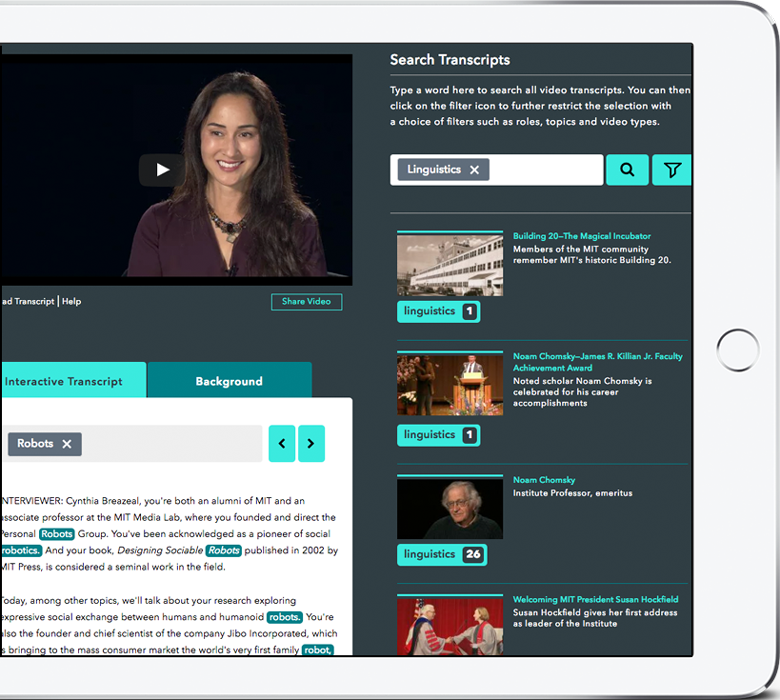
Platform Features
Your 3Play Media account lets you upload and manage files, monitor job status, preview and download transcripts and captions files, manage users, set up billing, use video search and clipping tools, and set up an interactive transcript or other video plugins.
Integrations
Integrations with Video Platforms and Lecture Capture
Connect 3Play effortlessly with your existing platforms. With 40+ integrations and custom API solutions, we fit into your workflow—so you can scale without disruption.















Flexible Upload Options
There are several ways to upload your video or audio files for processing:
- Secure Direct uploader (HTTPS)
- FTP
- Pasting links
- Directly from video platforms or lecture capture systems
- Upload from cloud storage
- API
All of these methods allow you to upload multiple videos at once. The 3Play Media system supports hundreds of media formats, including most web video and audio formats.
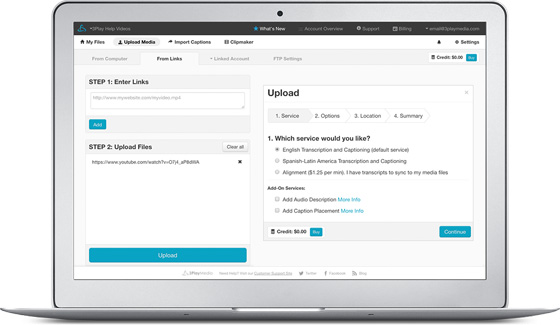
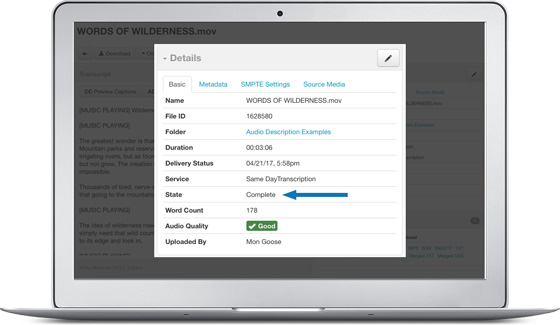
Tracking Job Status
Your account displays the real-time status of each file. You can also get email alerts to be notified when files have been completed.
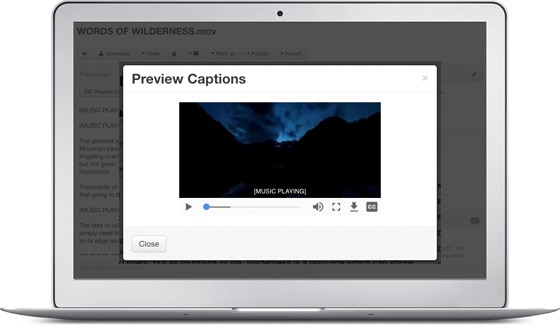
Captions Preview
After your media files have been processed, you can preview all the different captions formats with your video or audio before downloading.
Payment and Billing
Your account provides flexible payment and billing options, as well as detailed online invoicing. It can be setup to accommodate centralized billing across multiple departments or on a department by department basis.
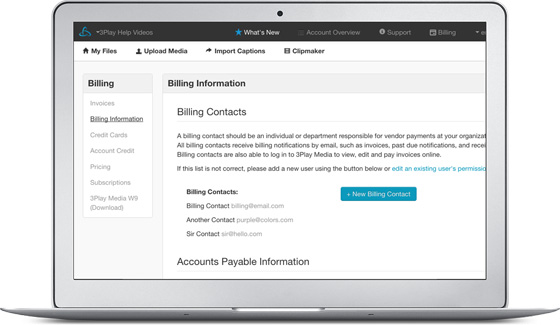
User & Account Management
Your account supports multiple users, departments, and permissions. Account admins can control user access to any of the core account functions: invoices & billing, uploading, editing, publishing control, and user management.
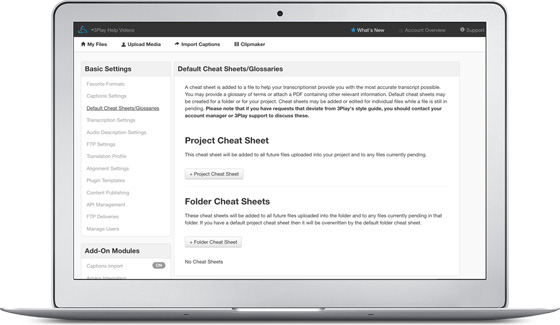
Cheatsheets
Upload cheatsheets, sometimes called order instructions, for your transcript editor to reference while editing. They can be preloaded on a file by file basis or applied to an entire folder or project. Cheatsheets typically include any relevant instructions for the transcript editor working on your content. For example, cheatsheets can direct the editor when or where to use specific speaker labels or acronyms in the transcript.
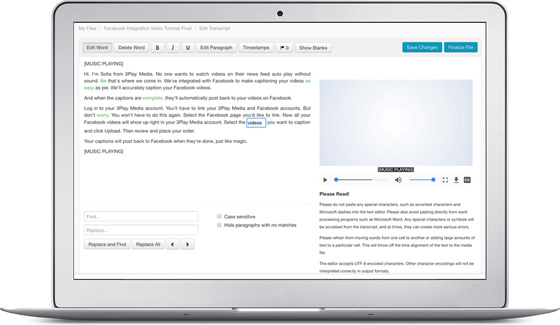
Captions Editor
Although rarely necessary, your account includes a captions text editor that allows you to quickly make changes or redactions to your captions or transcripts after they have been processed. Your edits propagate to all captions and transcript outputs, including video plugins that have already been published.
Video Plugins
In the account system, you can utilize our free 3Play Plugin which is fully customizable and compatible with most video players and publishing platforms, including LMS systems. With the 3Play Plugin, users can add captions, interactive transcripts, audio description and SEO to videos they don’t own and to video players that otherwise don’t support these features.